
![]()
![]()
![]()

![]()
![]()

cabinetry is a Python package to build and steer (profile likelihood) template fits.
It interfaces libraries developed within IRIS-HEP and the wider HEP Python ecosystem to make it easier for an analyzer to run their statistical inference pipeline.
The code can be found on GitHub: scikit-hep/cabinetry, while documentation is provided on readthedocs.
An example notebook runs through Binder to see cabinetry in action.
Many analyses at the LHC use the ROOT implementation of HistFactory or the newer pythonic implementation pyhf to construct their statistical model.
These models are built from template histograms.
It is the responsibility of the analyzers to define the event selection and variables of interest to fill the multitude of histograms required, including various systematic variations.
This task is well suited for automation, and tools like HistFitter and TRExFitter have been developed to address this need.
Those tools were designed to work with the ROOT implementation of HistFactory, and while they don’t have a shared declarative specification, there are many commonalities.
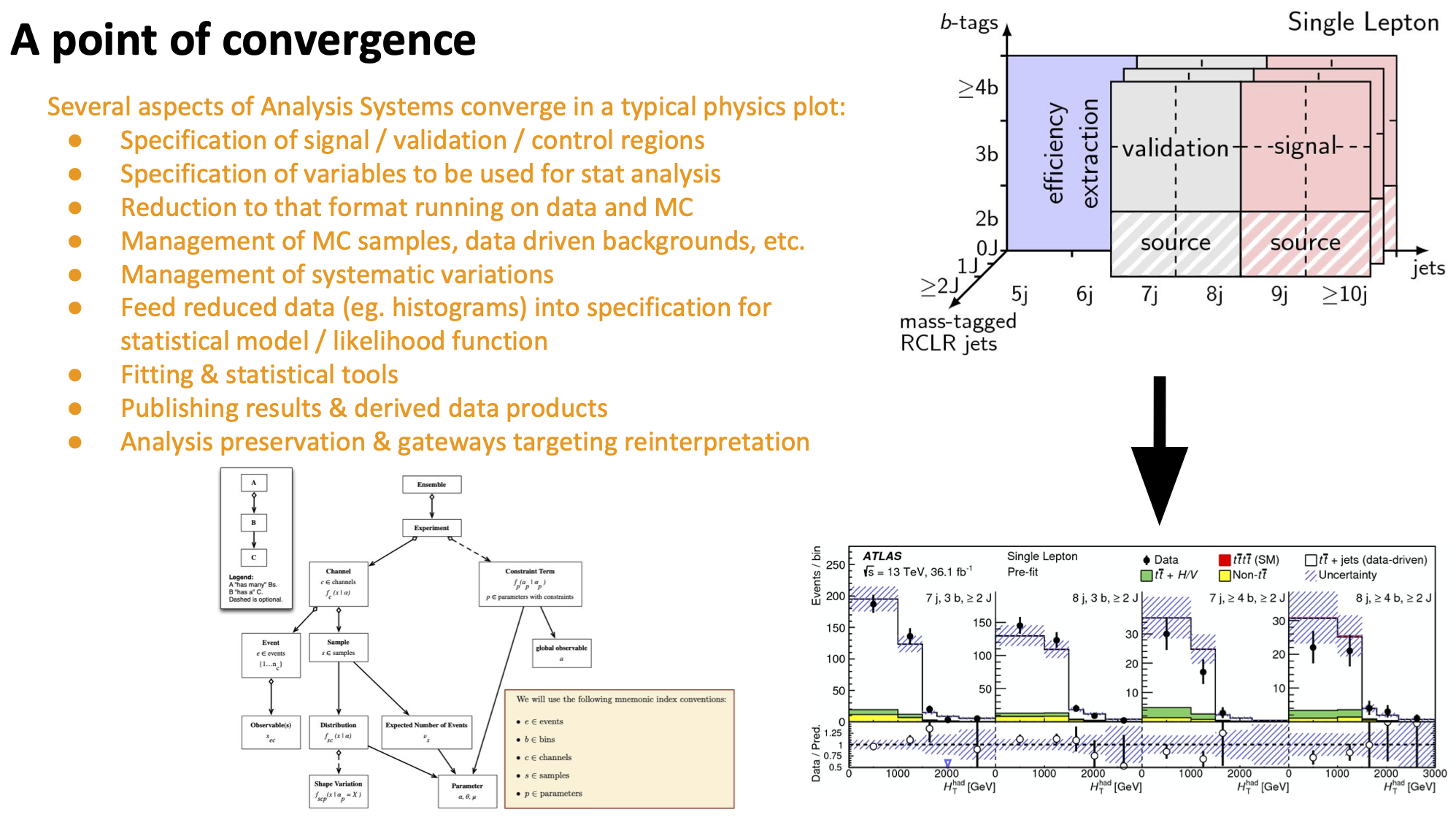
The cabinetry effort is a point of convergence for projects in the Analysis Systems focus area, and brings together many of the tools IRIS-HEP is developing.
Analyzers can use the cabinetry library to construct their statistical models and to perform inference with them.
Models are built from a declarative specification, which concisely summarizes the information needed to create all required template histograms and assemble them into a statistical model.
The execution of the required steps to construct a model is steered by cabinetry and makes use of libraries such as uproot and awkward-array.
cabinetry also provides functionality to perform inference and study fit results, including common types of associated visualizations.
Inference in cabinetry is performed via pyhf.
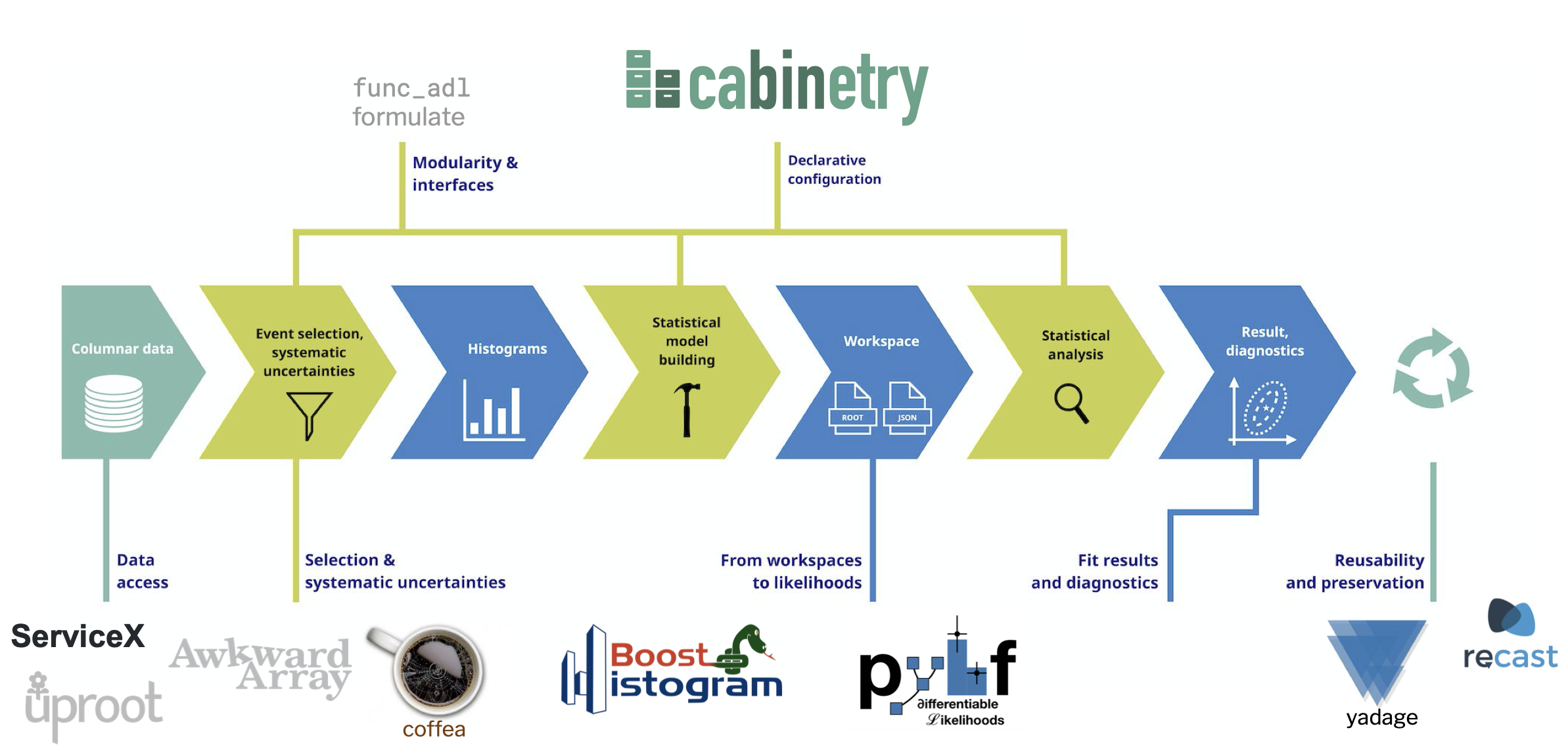
cabinetry in the IRIS-HEP ecosystem
The following image shows the final stages of an analysis: processing of columnar data to construct a statistical model, inference, and possible reuse and preservation. It shows examples of connections to other packages developed in IRIS-HEP and the wider ecosystem.
The poster below provides another look at final stages of an analysis. It describes the steps involved in the chain, and how they connect to other IRIS-HEP focus areas.

Team
Presentations
- 26 Feb 2026 - "HistFactory Introduction", Alexander Held, Simulation-Based Inference Blueprint
- 19 Nov 2024 - "Practical model building for statistical analysis", Alexander Held, ATLAS Lecture Series
- 19 Jul 2024 - "Statistical tools: pyhf and cabinetry", Alexander Held, US ATLAS / IRIS-HEP Analysis Software Training Event 2024
- 30 Jan 2024 - "Introduction to cabinetry", Alexander Held, ATLAS HHFramework meeting
- 4 Dec 2023 - "Constructing and steering pyhf models with cabinetry" , Alexander Held, pyhf Users and Developers Workshop 2023
- 26 Jul 2023 - "Statistical models, analysis workflows & automatic differentiation", Alexander Held, PyHEP.dev 2023
- 12 Apr 2023 - "cabinetry overview", Alexander Held, CMS Common Analysis Tools (CAT) general meeting
- 3 Mar 2023 - "cabinetry tutorial", Alexander Held, Belle II pyhf workshop
- 15 Sep 2022 - "End-to-end physics analysis with Open Data: the Analysis Grand Challenge", Alexander Held, PyHEP 2022 (virtual) Workshop
- 28 Jun 2022 - "pyhf tutorial", Alexander Held, Hybrid ATLAS Induction Day + Software Tutorial
- 9 Jun 2022 - "Introduction to pyhf and experience in the context of ATLAS", Alexander Held, ATLAS Statistics Forum Meeting
- 23 May 2022 - "Analysis user experience with the Python HEP ecosystem", Jim Pivarski, Analysis Ecosystems Workshop II
- 25 Apr 2022 - "Statistical inference: pyhf and cabinetry", Matthew Feickert, IRIS-HEP AGC Tools 2022 Workshop
- 25 Apr 2022 - "From data delivery to statistical inference with CMS Open Data", Alexander Held, IRIS-HEP AGC Tools 2022 Workshop
- 15 Mar 2022 - "Introduction to cabinetry", Alexander Held, ATLAS SUSY Background Forum
- 3 Nov 2021 - "From data delivery to statistical inference: ServiceX, coffea, cabinetry & pyhf", Alexander Held, IRIS-HEP AGC Tools 2021 Workshop
- 21 Sep 2021 - "pyhf and cabinetry", Alexander Held, ATLAS SUSY Workshop 2021
- 6 Jul 2021 - "Binned template fits with cabinetry", Alexander Held, PyHEP 2021 Workshop
- 19 May 2021 - "Building and steering template fits with cabinetry", Alexander Held, 25th International Conference on Computing in High Energy & Nuclear Physics
- 25 Feb 2021 - "The cabinetry library", Alexander Held, ATLAS Statistics Forum Meeting
- 26 Oct 2020 - "Template-based Fitting: cabinetry", Alexander Held, IRIS-HEP Future Analysis Systems and Facilities Blueprint Workshop
- 27 May 2020 - "cabinetry introduction", Alexander Held, 2020 IRIS-HEP Team Retreat
- 12 Mar 2020 - "pyhf and thoughts about analysis workflow", Alexander Held, ATLAS Statistics Committee Meeting
- 27 Feb 2020 - "Rethinking final analysis stages (poster)", Alexander Held, IRIS-HEP Poster Session
- 29 Oct 2019 - "Harmonizing statistics tools - ideas", Alexander Held, ATLAS Statistics Committee Meeting
- 19 Jun 2019 - "Template Fits: HistFitter / TRExFitter", Alexander Held, Analysis Systems Topical Meeting
Publications
- How the Scientific Python ecosystem helps answer fundamental questions of the Universe, Matthew Feickert, Nikolai Hartmann, Lukas Heinrich, Alexander Held, Vangelis Kourlitis, Nils Krumnack, Giordon Stark, Matthias Vigl, Gordon Watts, SciPy 2024 (10 Jul 2024).
- Publishing statistical models: Getting the most out of particle physics experiments, K. Cranmer et. al., SciPost Phys. 12 037 (2022) (10 Sep 2021) [56 citations] [NSF PAR].
- Building and steering binned template fits with cabinetry, K. Cranmer and A. Held, EPJ Web Conf. 251 03067 (2021) (23 Aug 2021) [23 citations] [NSF PAR].