Intelligent Data Delivery Service
The intelligent Data Delivery Service (iDDS) is a general service to orchestrate the workload management system and data management system and to transform and deliver needed data to consumers in order to improve the workflow between the workload management system and the data management system.
IDDS is an ongoing joint project within IRIS-HEP and US ATLAS in the DOMA and Analysis Systems area as well as within the HEP Software Foundation event delivery group.
R&D Significance and Impact
- Data Carousel for LHC: iDDS enables fine-grained prompt processing to efficiently use disk storage. The data carousel has been in production for more than 2 years and is an essential to ATLAS’s strategy for minimizing disk buffer requirements for the HL-LHC.
- iDDS hyperparameter optimization service is used for the new ML (GAN) based component in production fast simulation (AtlFast3), FastCaloGAN. The HPO service allows for effective HPC GPU utilization, clouds, and other distributed resources for ML.
- iDDS DAG-based workflow service provides, with PanDA, the ability to manage the inter-dependencies of different jobs in a workflow. This service has been additionally adopted by the Vera Rubin observatory for its data processing needs.
- Ongoing R&D - a growing number of analysis use cases that are demanding in their complexity and resource needs. The iDDS team is exploring the use of the system ffor active learning, toy MC generation, workflows with REANA.
Benefits
- Experiment-agnostic service, already employed by ATLAS experiment and Vera Rubin Observatory. The sPHENIX experiment is exploring its potential uses.
- Fine-grained data carousel workflow addressing the HL-LHC storage challenge to reduce storage usage.
- Scable Machine Learning service to efficiently distribute ML hyperparameter optimization tasks and so on to distributed HPC/GPU resources.
- Complex dynamic workflow management, such as DAG (Directed Acyclic Graphs), Loop workflow, Template workflow and Condition workflow, to automate complex production and analysis workflows. It has been used in different experiments, such as ATLAS hyperparameter optimization, ATLAS Active Learning, ATLAS REANA production+analysis integration workflow, Rubin data processing and near-term sPHENIX processing.
- Operating on traditional distributed High Throughput Computing capacity, commercial clouds, and HPCs.
- Future developmen projects include fine-grained data transformation and delivery for remote analysis.
Use Cases
-
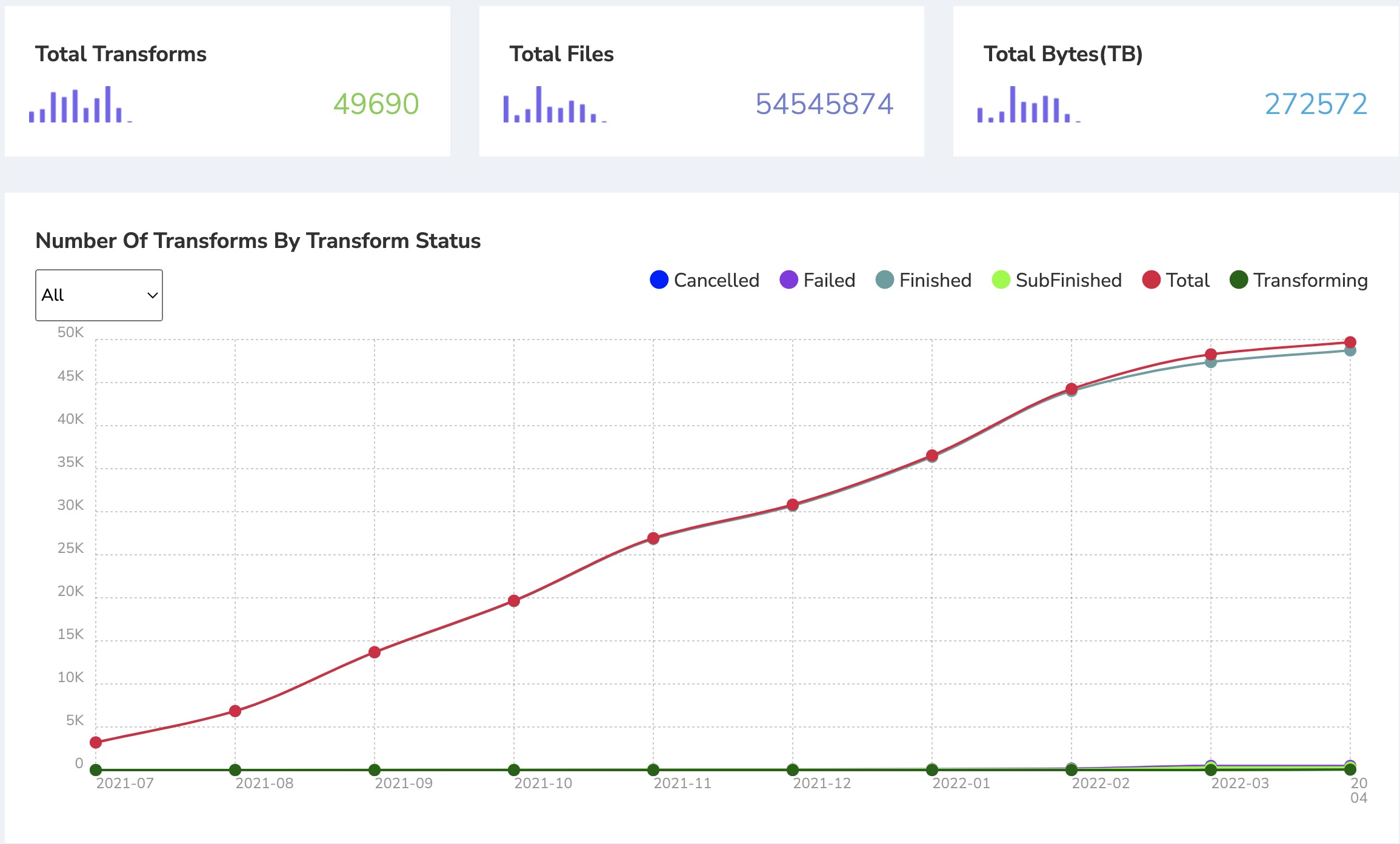
ATLAS Data Carousel: If HL-LHC is going to process exabytes of data, it needs data access systems that can deliver. The iDDS attempts to make the workflow system more aware of the data workflows and get data processed more effectively. The ATLAS “data carousel” is the initial use case for iDDS. It orchestrates the processing of data as soon as it comes out of archival systems instead of waiting for entire datasets to be staged. This minimizes the use of disk buffers – especially relevant for HL-LHC as the size of the disk buffer shrinks compared to the total dataset volumes.
iDDS performs the fine grained choreography between the processing workflow and dataflow management, initiating processing and deletion quickly at the file level when the data is staged from the tape, rather than when the entire datasets reach the disk as in the pre-iDDS system. ATLAS has been expanding the number of workflows using data carousel, now extending to most production workflows. The iDDS minimizes the delay between data being staged and being processing, reducing the data pinning time so that it can be deleted as soon as possible if required, so that it reduces the storage usage.
Over the two years that the iDDS-enabled data carousel has been in production. Several hundreds of PB data has been processed. (The monitor snapshot below only shows data from July 2021. The data before it is already archived.)
-
Hyper Parameter Optimization (HPO): HPO is a scable machine learning service to efficiently distribute ML tasks to distributed HPC/GPU resources. It is of interest to both HL-LHC Computing R&D and ML-based analysis for the potential to use large scale computing resources, such as HPCs and distributed GPUs, to reduce latencies within the development and refinement of ML applications by order of magnitude.
iDDS HPO, integrated with PanDA workload management system, has provides a fully-automated platform for ML hyper parameter optimization, and also similar tasks, on top of geographically distributed GPU resources on the grid, HPC, and clouds.
The PanDA/iDDS based ML service is the basis for optimizing the first ML application to reach production in the ATLAS fast simulation; the new AtlFast3 simulation that began production in 2021 incorporates FastCaloGAN, which uses PanDA/iDDS to accelerate its optimization of 300 neural networks requiring 100 GPU-days for a single pass.
Recently a new use case of the MC toy based confidence limits estimation, has adapted to use the iDDS HPO framework to manage its toy generation workflow with multiple steps.
Future development activities for HPO include a Jupyter-based interface and improved container runtime to simplify the user interface and the ML environment management.
-
DAG based workflow management: The iDDS internally implements a high-level workflow engine, specifying a set of interdependent jobs as described by DAG. iDDS, interacting with software such as PanDA, drives workload scheduling and implements management of job chains for multi-step processing with thousands of jobs per step.
The iDDS DAG’s impact goes beyond HL-LHC use cases and is used by the Vera Rubin Observatory. It enabled the smooth integration of PanDA into Rubin’s workflow and middleware, which together with successful PanDA scaling tests was instrumental in Rubin’s adoption of PanDA and iDDS in August 2021.
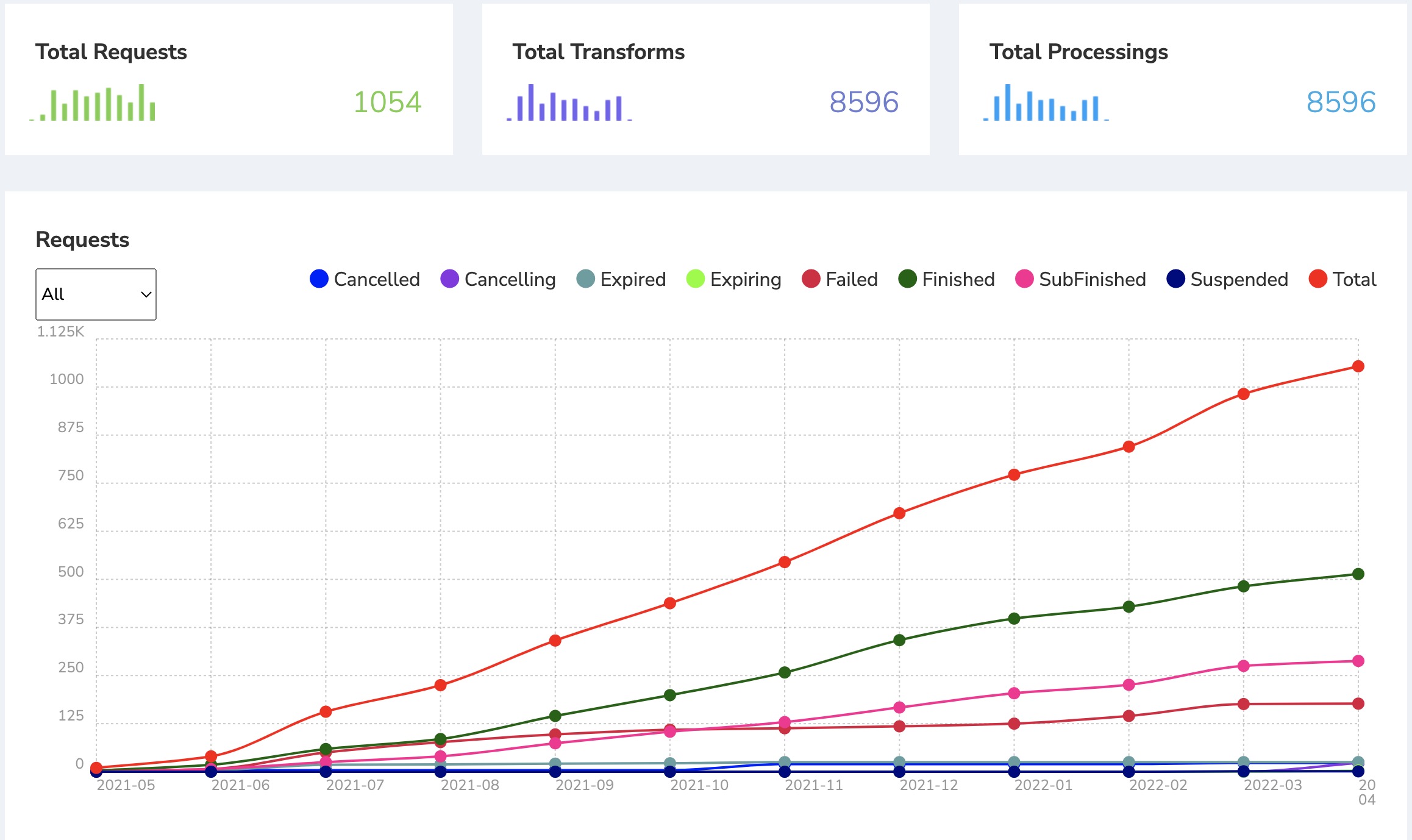
The DAG support then catalyzed a rapid proliferation of implemented complex workflows of interests to the ATLAS HL-LHC computing R&D and analysis communities. To enhance the workflow management, iDDS has implemented complex, dynamic workflow management such as Loop workflow, Template workflow and Condition workflow, to meet the requirements of some applications such as ATLAS Active Learning. The iDDS workflow management has been used to support a still growing set of complex workflow management applications, such as ATLAS MC toy based confience limits, ATLAS REANA production and analysis integration, and sPHINX workflow management.
-
Monte Carlo Toy Based Confidence Limits with iDDS: An efficient Monte Carlo Toy generation process requires multiple steps of grid scans, where current steps depends on the previous steps. The HPO framework is employed to provide a fully-automated platform for Toy generations.
iDDS has recently successfully demonstrated to execute these MC Toy workflows and is working on documentation and client integration.
-
Active Learning with iDDS, PanDA, and REANA: Active Learning is one of the ideas that require complex interactions between tasks in an analysis workflow. iDDS is employed for workflow managements, PanDA for task management, and REANA for analysis tasks definitions.
The iDDS team has successfully demonstrated active learning for demo workflows and is working to adapt this work to real analysis workflows.
-
sPHENIX workflow management: As a wider impact of IRIS-HEP software, sPHENIX experiment is testing the use of iDDS for their workflow management solution.
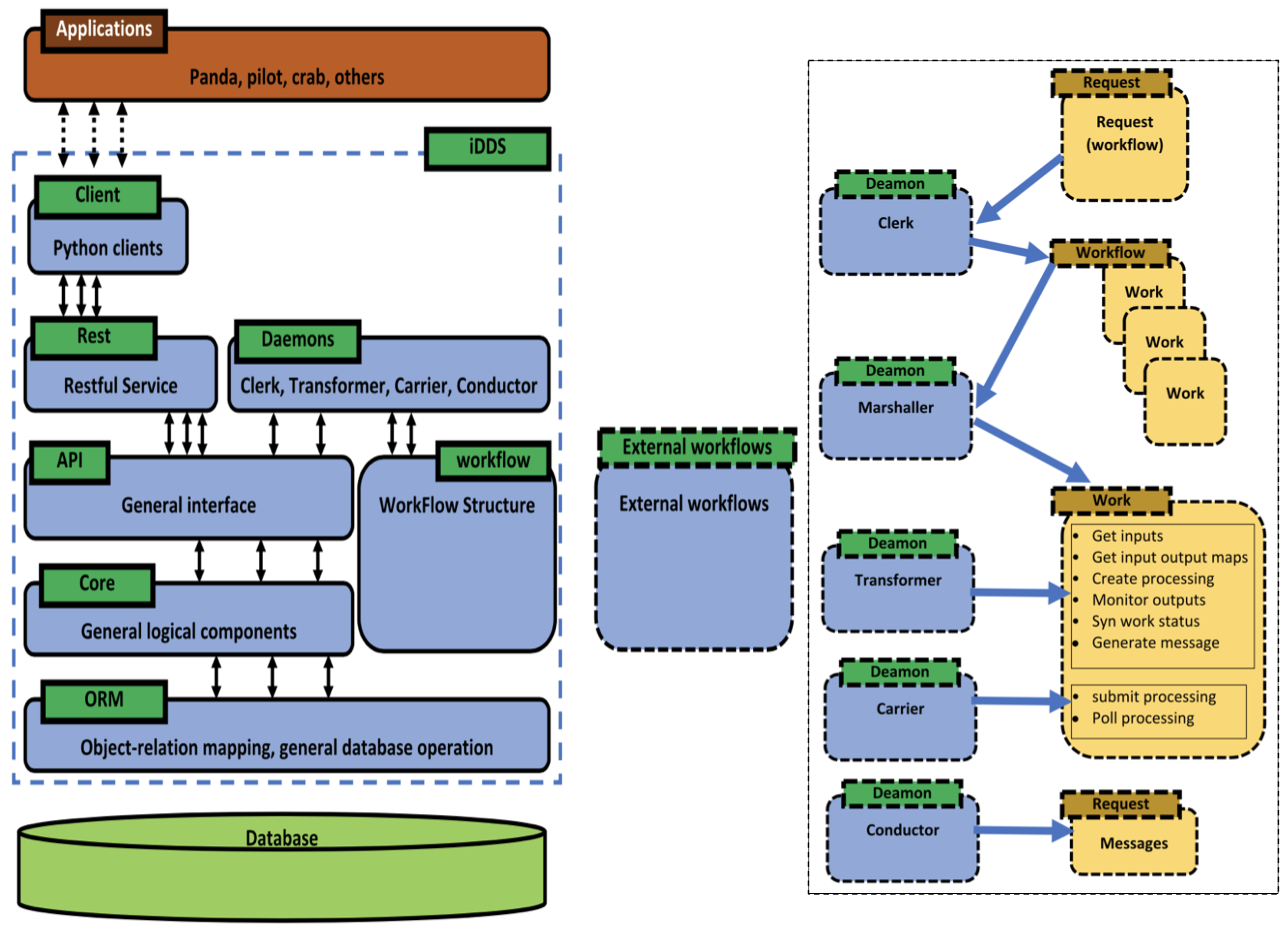
Component Architecture:
The iDDS component architecture is shown below (figure is reproduced from a 2021 paper on iDDS submitted to vCHEP2021):
Reference
- Home page
- Github source code repository
- Technical and User Documentation
- ATLAS instance monitor, ATLAS request monitor
- DOMA instance monitor, DOMA request monitor, DOMA workflow monitor
Team
- Brian Bockelman
- Wen Guan
- Tadashi Maeno
- Rui Zhang
- Tuan Minh Pham
Presentations
- 3 Mar 2022 - "Monte Carlo Toy Based Confidence Limits with iDDS (presented by Christian Weber)", Wen Guan, ADC WFMS weekly meeting
- 3 Mar 2022 - "REANA / PanDA integration for active learning", Wen Guan, ADC WFMS weekly meeting
- 10 Jan 2022 - "An intelligent Data Delivery Service (iDDS) for and beyond the ATLAS experiment", Wen Guan, 30th International Symposium on Lepton Photon Interactions at High Energies
- 12 Jul 2021 - "An intelligent Data Delivery Service (iDDS) for and beyond the ATLAS experiment", Wen Guan, 2021 Meeting of the Division of Particles and Fields of the American Physical Society (DPF21)
- 16 Jun 2021 - "iDDS", Wen Guan, ADC @ ATLAS Software & Computing Week
- 3 Jun 2021 - "update on iDDS", Wen Guan, ATLAS ADC WFMS meeting
- 18 May 2021 - "An intelligent Data Delivery Service for and beyond the ATLAS experiment", Wen Guan, 25th International Conference on Computing in High-Energy and Nuclear Physics(vCHEP2021)
- 29 Mar 2021 - "intelligent Data Delivery Service", Wen Guan, HL-LHC R&D topics
- 27 Jan 2021 - "iDDS active learning status and iDDS plans", Wen Guan, ADC @ ATLAS Software & Computing Week
- 21 Jan 2021 - "iDDS 2021", Wen Guan, ATLAS ADC WFMS meeting
- 5 Oct 2020 - "iDDS: new workflow structure", Wen Guan, ADC @ ATLAS Software & Computing Week
- 1 Oct 2020 - "iDDS news for machine learning", Wen Guan, Joint Atlas Machine Learning / Workflow Management Meeting
- 9 Jul 2020 - "iDDS for machine learning", Wen Guan, Joint Atlas Machine Learning / Workflow Management Meeting
- 15 Jun 2020 - "iDDS HyperParameter Optimization development for machine learning", Wen Guan, ATLAS Software & Computing Week
- 28 May 2020 - "iDDS integration", Wen Guan, ATLAS ADC WFMS meeting
- 11 Mar 2020 - "iDDS: A New Service with Intelligent Orchestration and Data Transformation and Delivery", Wen Guan, 3rd Rucio Community Workshop
- 27 Feb 2020 - "intelligent Data Delivery Service (iDDS) (Poster)", Wen Guan, IRIS-HEP poster session
- 7 Nov 2019 - "Event Streaming Service for ATLAS Event Processing", Wen Guan, 24th International Conference on Computing in High Energy Physics(CHEP2019)
- 30 Sep 2019 - "IDDS", Wen Guan, HSF & ATLAS Joint Event Delivery Workshop
- 24 Jun 2019 - "Delivery of columnar data to analysis systems", Marc Weinberg, ATLAS Software & Computing Week #62
- 20 Mar 2019 - "WLCG DOMA TPC Updates", Brian Bockelman, 2019 Joint HSF/OSG/WLCG Workshop (HOW2019)
- 6 Feb 2019 - "IRIS-HEP DOMA", Brian Bockelman, IRIS-HEP Steering Board Meeting
Publications
- An intelligent Data Delivery Service for and beyond the ATLAS experiment, W. Guan, T. Maeno, B. Bockelman, T. Wenaus, F. Lin, S. Padolski, R. Zhang and A. Alekseev, EPJ Web Conf. 251 02007 (2021) (28 Feb 2021) [9 citations] [NSF PAR].
- Towards an Intelligent Data Delivery Service, Wen Guan, Tadashi Maeno, Gancho Dimitrov, Brian Paul Bockelman, Torre Wenaus, Vakhtang Tsulaia, Nicolo Magini, CHEP2019 (14 Mar 2020).