
The sheer volume of HL-LHC events will emphasize the need for rapid data reduction and the ability to pull individual columns from complex datasets into high-speed data analysis facilities.
ServiceX is a data extraction and data delivery service. Users provide a dataset identifier and a selection statement that specifies filters and columns. ServiceX brings up parallel workers to open the files in the dataset and uses experiment approved frameworks to extract the data and store it in popular columnar file formats for easy analysis using familiar tooling.

Benefits
- ServiceX can be co-located with datasets to provide fast and efficient data reduction strategies.
- Interface is easy to learn and the processes are extremely reliable to make it easy for analyzers to get their job done without needing to learn complex libraries and closely monitor hand-written batch jobs
- Extracts data from experiment-specific data formats using approved frameworks.
- Data can be provided as popular and powerful Awkward Arrays which integrates with the ecosystem of analysis tools within IRIS-HEP.
- Results can be written to an object store or to SkyHook Volumes
- Results are cached locally to allow for easy straightforward reuse of data.
- Transformers are run out of tagged docker images to allow for precise reproducibility
- Works seamlessly as a data backend to Coffea and TRExFitter analysis tools
Performance
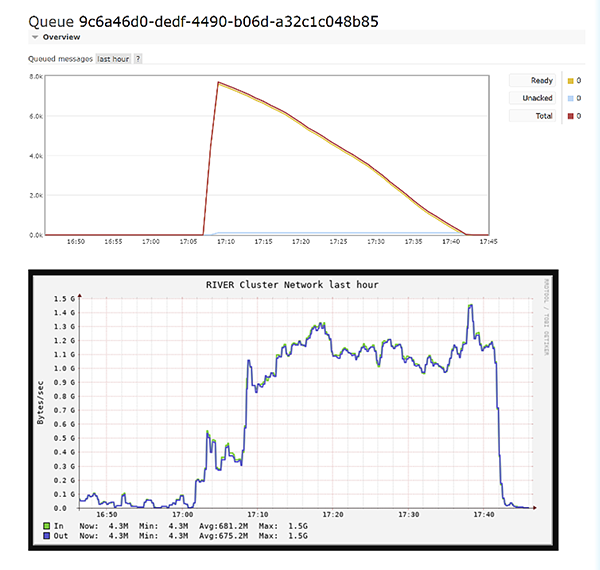
Recent testing on 10 TB xAOD input sample where we requested 100 columns from 7 collections (~30% of file). We were able to scale up to 1,000 workers the River SSL Cluster to get results in less than 30 minutes. Output rate was in excess of 300MB/s.
How It Works
The dataset lookup service is extensible and developers can create new services to meet the needs of a specific community. Currently, datasets can be requested using a Rucio DID or as a reference to a CERN OpenData dataset. Users can also provide a set of accessible file URLs.
The files located by the lookup service are passed to transformer workers which are spun up to filter data and extract columns. These transformer workers run out of docker images which are based on experiment approved images. Their operation is controlled by a low-level selection language called Qastle. This language allows for filtering of events as well as data projections and simple calculations of derived values.
Qastle is useful for concisely communicating these transform requests, however is not intended for end-users. Instead, there are translators that transpile high level selection languages. There are currently transpilers for func_adl and for the T-Cut language.
Architecture
ServiceX uses a micro-service architecture that runs on a Kubernetes cluster. Users interact with the service via a REST interface provided by a Flask App. The app also provides orchestration of the other components.
The Qastle queries are translated into event framework code by code generator services. These can generate C++ or Python Uproot code which is executed by the transformers.
The transformers are launched as an auto-scaling job by the flask app. Each worker is fed from a transactional RabbitMQ queue.
Reference
Full documentation at the Servicex ReadTheDocs pages.

ServiceX talk at HSF DAWG – DOMA Access meeting
Keep in Touch
Sign up for the ServiceX Mailing List to be informed of new releases of the system.
Team
- Andrew Eckart
- Ben Galewsky
- Rob Gardner
- Lindsey Gray
- Mark Neubauer
- Jim Pivarski
- Ilija Vukotic
- Gordon Watts
- Marc Weinberg
- Michael Johnson
Presentations
- 27 May 2026 - "ServiceX in the ATLAS Integration Challenge: Data Delivery for HL-LHC Analyses", Giordon Stark, 28th Conference on Computing in High Energy and Nuclear Physics (CHEP 2026)
- 27 May 2026 - "ServiceX Update", Ben Galewsky, 28th Conference on Computing in High Energy and Nuclear Physics (CHEP 2026)
- 23 Feb 2026 - "ServiceX for the ALTAS integration challenge pipeline - ML framework.", Artur Cordeiro Oudot Choi, Integration Challenge workshop
- 22 Jan 2026 - "Distributing Community MCP Servers", Ben Galewsky, ESIP January Meeting 2026
- 20 Jan 2026 - "Teaching Machine Learning Techniques Using Agentic Coding", Ben Galewsky, ESIP January Meeting 2026
- 13 Nov 2025 - "Using ServiceX for ATLAS OpenData", Artur Cordeiro Oudot Choi, Open Data Meeting, ATLAS Internal
- 14 Oct 2025 - "AMG - Looking Forward", Gordon Watts, ATLAS Week
- 9 Oct 2025 - "ATLAS integration challenge.", Artur Cordeiro Oudot Choi, IRIS-HEP institute retreat
- 22 Sep 2025 - "IRIS-HEP and ATLAS", Gordon Watts, ATLAS Software & Computing Week [private]
- 22 Sep 2025 - "LLMs for physics software", Gordon Watts, ATLAS Software & Computing Week [private]
- 10 Sep 2025 - "ServiceX: Streamlining Data Delivery and Transformation for HL-LHC Analyses", Artur Cordeiro Oudot Choi, ACAT2025 Workshop
- 8 Sep 2025 - "Using ServiceX to prepare training data for an ATLAS Long-Lived Particle Search", Gordon Watts, ACAT - 2025
- 8 Sep 2025 - "Applying Transaction Processing Techniques to Large Scale Analysis", Ben Galewsky, ACAT 2025
- 5 Sep 2025 - "LLMs for physics software", Gordon Watts, Build Big or Build Smart: Examining Scale and Domain Knowledge in Machine Learning for Fundamental Physics
- 25 Jul 2025 - "IRIS-HEP ServiceX Tutorial", Artur Cordeiro Oudot Choi, US ATLAS / IRIS-HEP Analysis Software Training Event 2025
- 8 Jul 2025 - "ServiceX", Peter Onyisi, US CMS Analysis Facility Meeting
- 6 May 2025 - "Analysis at the HL-LHC: Data Delivery, ServiceX, and Addressing Our Analysis Challenges", Gordon Watts, WLCG/HSF Workshop - 2025
- 15 May 2024 - "Cloud Data Lake Technologies", Ben Galewsky, WLCG/HSF Workshop
- 11 Mar 2024 - "ServiceX, the novel data delivery system, for physics analysis", KyungEon Choi, ACAT 2024
- 11 Mar 2024 - "From Amsterdam to ACAT 2024: The Evolution and Convergence of Declarative Analysis Language Tools and Imperative Analysis Tools", Gordon Watts, ACAT 2024
- 4 Oct 2023 - "The AGC with ATLAS Data", Gordon Watts, The ATLAS Software And Computing Week #76 (internal)
- 11 May 2023 - "Data Management Package for the novel data delivery system, ServiceX, and Applications to various physics analysis workflows", KyungEon Choi, CHEP 2023 Conference
- 15 Sep 2022 - "End-to-end physics analysis with Open Data: the Analysis Grand Challenge", Alexander Held, PyHEP 2022 (virtual) Workshop
- 14 Sep 2022 - "Data Management Package for the novel data delivery system, ServiceX, and its application to an ATLAS Run-2 Physics Analysis Workflow", KyungEon Choi, PyHEP 2022 Workshop
- 23 May 2022 - "Analysis user experience with the Python HEP ecosystem", Jim Pivarski, Analysis Ecosystems Workshop II
- 25 Apr 2022 - "From data delivery to statistical inference with CMS Open Data", Alexander Held, IRIS-HEP AGC Tools 2022 Workshop
- 30 Nov 2021 - "ServiceX - Making everything Columnar", Gordon Watts, ACAT 2021
- 3 Nov 2021 - "From data delivery to statistical inference: ServiceX, coffea, cabinetry & pyhf", Alexander Held, IRIS-HEP AGC Tools 2021 Workshop
- 9 Jul 2021 - "Using Python, coffea, and ServiceX to Rediscover the Higgs. Twice." , Gordon Watts, PyHEP 2021
- 19 May 2021 - "Towards Real-World Applications of ServiceX, an Analysis Data Transformation System", KyungEon Choi, CHEP 2021 Conference
- 19 Apr 2021 - "ServiceX On-Demand Data Transformation and Delivery, and Applications", KyungEon Choi, APS 2021
- 26 Oct 2020 - "Data Selection & Delivery for Analysis: ServiceX & funcADL", Mason Proffitt, Future Analysis Systems and Facilities
- 16 Oct 2020 - "ServiceX Front End Status", Gordon Watts, ServiceX Meeting
- 2 Oct 2020 - "ServiceX Front End Status", Gordon Watts, ServiceX Meeting
- 14 Jul 2020 - "ServiceX On-Demand Data Transformation and Delivery for the Present and HL-LHC Era", KyungEon Choi, PyHEP 2020 Workshop
- 8 Jul 2020 - "ServiceX and Kubernetes", Ben Galewsky, LHCG Grid Deployment Board meeting
- 26 May 2020 - "Parallel Sessions: Plans and Goals", Gordon Watts, IRIS-HEP Team Retreat
- 4 Nov 2019 - "A Distributed, Caching, Columnar Data Delivery Service(X)", Ben Galewsky, CHEP 2019 Conference
- 19 Jun 2019 - "ServiceX", Ben Galewsky, Analysis Systems Topical Workshop
Publications
- Data Management Package for the novel data delivery system, ServiceX, and Applications to various physics analysis workflows, K. Choi and P. Onyisi, EPJ Web Conf. 295 06008 (2024) (08 May 2023).
- Towards Real-World Applications of ServiceX, an Analysis Data Transformation System, K. Choi, A. Eckart, B. Galewsky, R. Gardner, M. Neubauer, P. Onyisi, M. Proffitt, I. Vukotic and G. Watts (23 Aug 2021).
- ServiceX A Distributed, Caching, Columnar Data Delivery Service, ServiceX A Distributed, Caching, Columnar Data Delivery Service B. Galewsky, R. Gardner, L. Gray, M. Neubauer, J. Pivarski, M. Proffitt, I. Vukotic, G. Watts, M. Weinberg EPJ Web Conf. 245 04043 (2020) DOI: 10.1051/epjconf/202024504043 (16 Nov 2020).
- Snowmass 2021 Letter of Interest: Analysis Ecosystem at the HL-LHC, G. Watts Snowmass 2021 Letter of Interest (10 Sep 2020).