Skyhook Data Management
Overview
HL-LHC will challenge existing storage systems with regards to both data volumes and velocity: analysis datasets will grow significantly and users will demand higher event rates to improve the time-to-insight. The SkyHook DM project is an investment into computational storage, relying on the insight that the data organization of HEP files is highly structured. The service is able to recognize the layout of files and “push down” structured queries from client to server, taking advantage of the computational capacity in the storage hardware and reducing data movement significantly.
Combining data management with storage also creates the opportunity for new services that can help avoid dataset copies and thereby can significantly save storage space. Data management-enabled storage systems can provide views by combining parts of multiple datasets. For HEP this means that columns from one table can be combined with columns from a different table without creating copies. For this to work, these storage systems need to store sufficient metadata and naming conventions about datasets. This makes them a natural place for maintaining this metadata and servicing it to other tools in convenient formats.
Skyhook Data Management is an extension of the Ceph open source distributed storage system for the scalable storage of tables and for offloading common data management operations on them, including selection, projection, aggregation, and indexing, as well as user-defined functions. The goal of SkyhookDM is to transparently scale out data management operations across many storage servers leveraging the scale-out and availability properties of Ceph while significantly reducing the use of CPU cycles and interconnect bandwidth for unnecessary data transfers. The SkyhookDM architecture is also designed to transparently optimize for future storage devices of increasing heterogeneity and specialization. All the data movements from the Ceph OSDs to the client happen in Apache Arrow format.
SkyhookDM is currently an incubator project at the Center for Research on Open Source Software at the University of California Santa Cruz.
Salient Features
-
Enables pushing down filters, projections, compute operations to the Storage backend for minimal data transfer over the network and linear scalability.
-
Allows storing data in Parquet files for minimizing Disk I/O though predicate and projection pushdown.
-
Allows writing files to a POSIX filesystem interface.
-
Minimal deployment overhead either via Rook or Ceph-Deploy.
-
Plugs-in seamlessly into the Arrow Dataset API and leverages all its functionality like dataset discovering, partition pruning, etc.
-
Works with latest Apache Arrow and latest Ceph versions.
Architecture
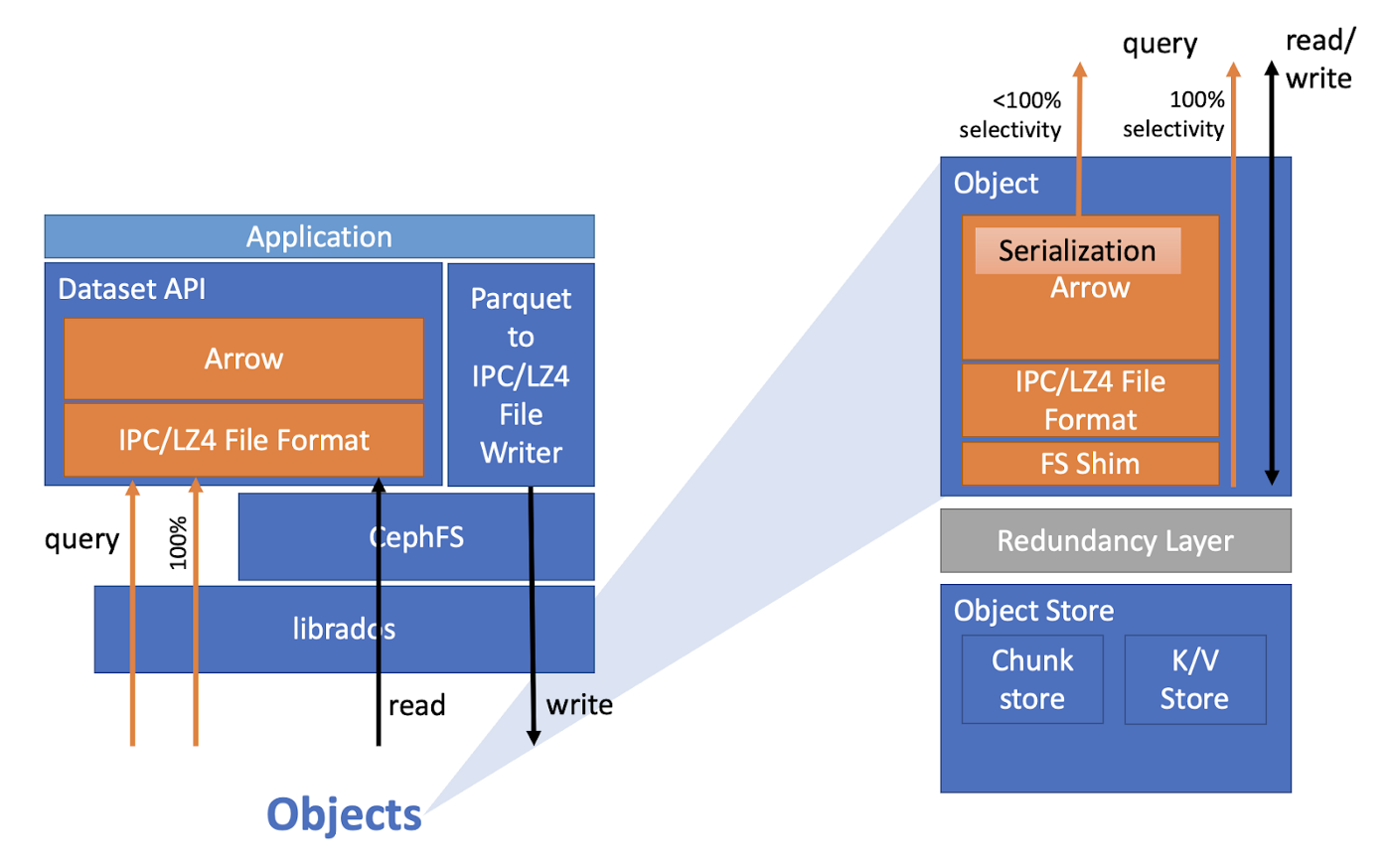
In the storage layer, we extend the Ceph Object Store with plugins built using the Object Class SDK to allow scanning objects containing Parquet data inside the Ceph OSDs. We utilize the Apache Arrow framework for building the data processing logic in the plugins. On the client side, we extend CephFS with a SkyhookDirectObjectAccess API that allows invoking Object Class methods on RADOS objects to perform query operations. We export our implementation by creating a new FileFormat in Apache Arrow called SkyhookFileFormat that uses the SkyhookDirectObjectAcess API to offload Parquet file scanning to the storage layer.
Performance Evaluation
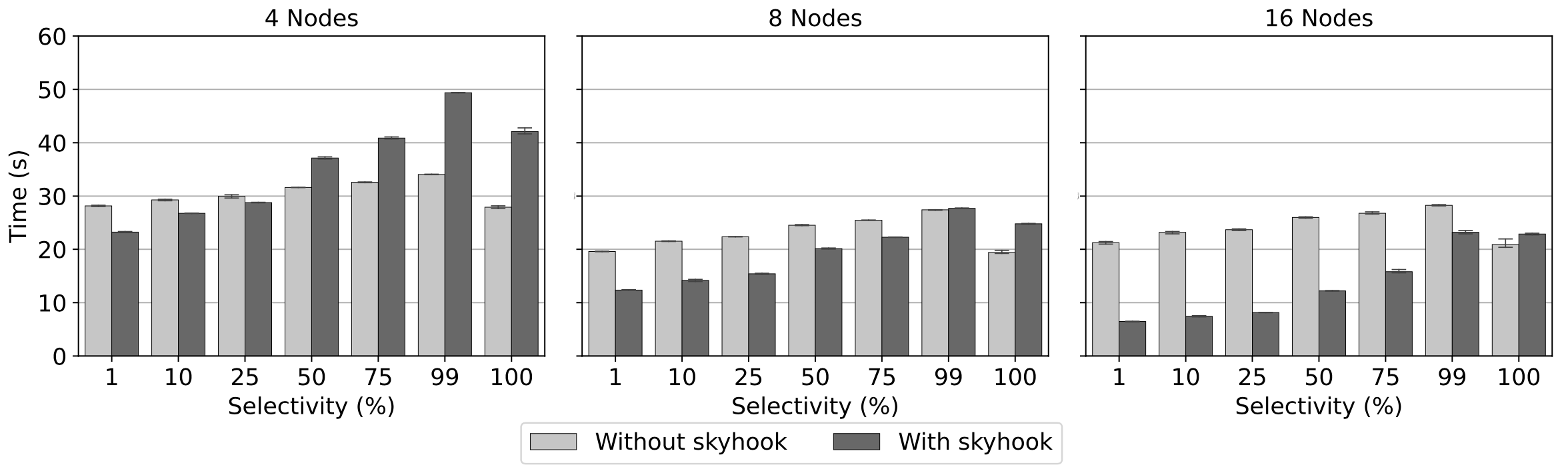
We compare the query latencies of filtering a 1.2 billion row dataset via Parquet and Skyhook file formats with 1%, 10%, and 100% row selectivities. As shown in the above plot, Parquet performance doesn’t improve on scaling out from 4 to 16 nodes as it stays bottlenecked on the client’s CPUs. On the other hand, performance of Skyhook improves as it can distribute CPU consumption amongst the storage nodes and can scale out almost linearly.
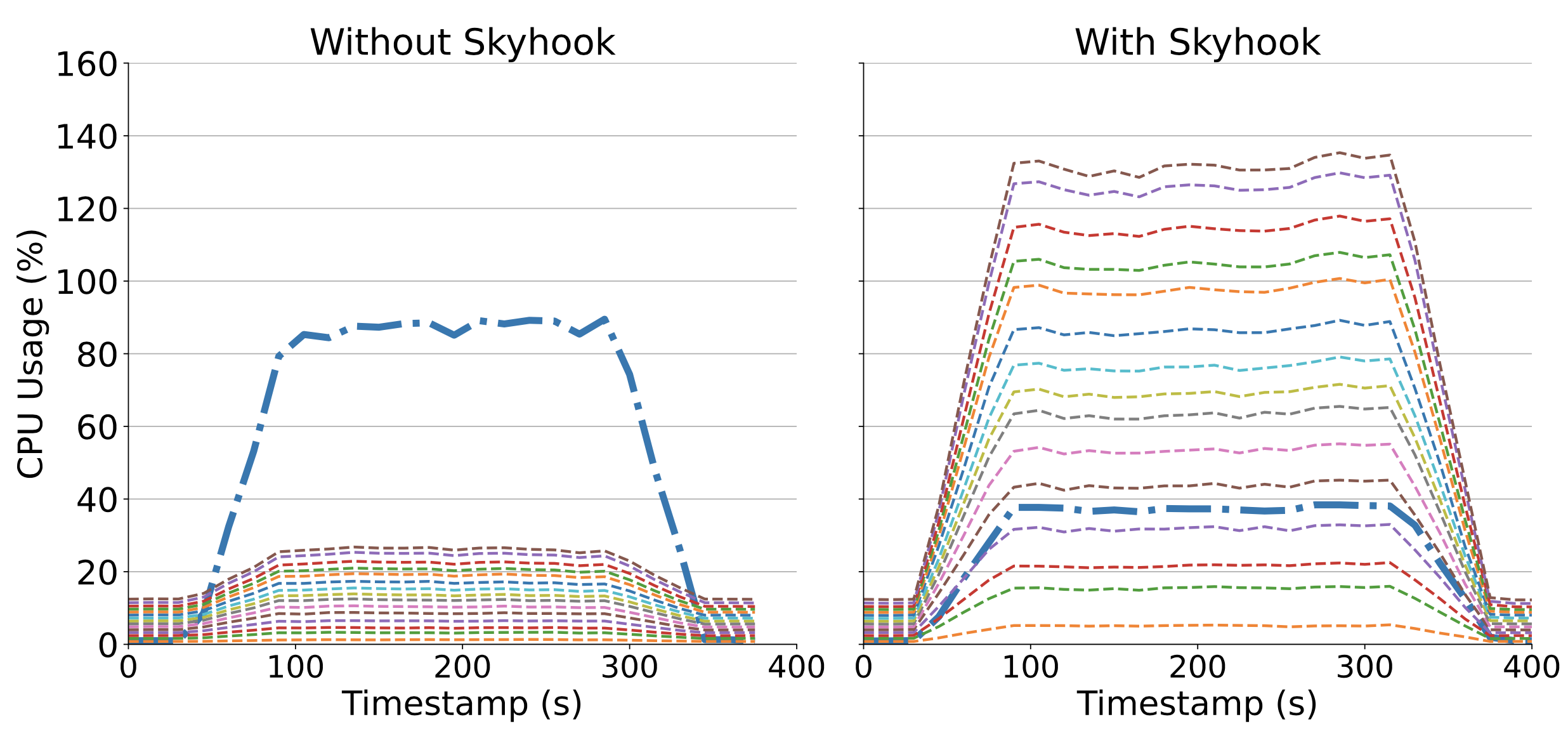
The above two plots shows how Parquet (top) stays bottlenecked on the client CPU while Skyhook (bottom) distributes CPU usage between the storage nodes and allows scale out.
Ongoing Work
-
Working on making the Coffea-Skyhook integration more user-friendly.
-
A middleware to allow writing Parquet files containing Nanoevents from ServiceX to SkyhookDM via CephFS.
Important Links
- Github repository.
- Getting started instructions and notebook.
- Code walkthrough video.
Announcements
- April, 2022 - Skyhook is deployed at UNL and at the SSL at the University of Chicago.
- March, 2022 - Skyhook: Toward an Arrow-Native Storage System, to appear in CCGrid 2022.
- January, 2022 - Skyhook: Bringing Computation to Storage with Apache Arrow
- October, 2021 - Skyhook is now a part of Apache Arrow !
- December, 2021 - SkyhookDM v0.4.0 Released !
- July, 2021 - SkyhookDM v0.3.0
- March, 2021 - SkyhookDM v0.1.1 Released !
- February, 2021 - SkyhookDM v0.1.0 Released !
- February, 2021 - Guide for getting started with SkyhookDM.
Fellows
- Jayjeet Chakraborty (current)
- Xiongfeng Song (former)
Team
Presentations
- 2 Dec 2022 - "Open Source Program Offices in Research Universities", Carlos Maltzahn, CHPC National Conference 2022
- 28 Sep 2022 - "Birds of a Feather: Pathways to Enable an Open Source Ecosystem for the Skyhook Project", Carlos Maltzahn, 2022 UC Santa Cruz Open Source Symposium
- 27 Sep 2022 - "Welcome & Introductions", Carlos Maltzahn, 2022 UC Santa Cruz Open Source Symposium
- 23 Jun 2022 - "HPC Panel at the Data Thread", Carlos Maltzahn, The Data Thread Conference
- 13 Jun 2022 - "Skyhook Blueprint for Computational Storage, a Case for Amplifying Research Impact via Open Source", Carlos Maltzahn, Research and Practice Colloquium at Friedrich-Alexander-Universität, Erlangen-Nürnberg, Germany
- 23 May 2022 - "Analysis user experience with the Python HEP ecosystem", Jim Pivarski, Analysis Ecosystems Workshop II
- 17 May 2022 - "Skyhook: Towards an Arrow-Native Storage System", Jayjeet Chakraborty, CCGrid22
- 6 Apr 2022 - "Creating an OSPO at the University of California", Carlos Maltzahn, OSPOlogy: How Academic OSPOs are Amplifying Research Impact
- 25 Mar 2022 - "Faculty and Student Session: Open Source Research Experience (OSRE)", Carlos Maltzahn, The Association of Computer Science Departments at Minority Institutions (ADMI) High Performance Computing and Gateways 2022 Symposium (ADMI 2022)
- 2 Feb 2022 - "Creating an OSPO at the University of California", Carlos Maltzahn, OSPO++ Academic Track: UC Santa Cruz and UVM on setting up an OSPO
- 4 Nov 2021 - "Skyhook Data Management", Carlos Maltzahn, Analysis Grand Challenge Tools 2021 Workshop
- 2 Nov 2021 - "Towards an OSPO at the University of California", Carlos Maltzahn, Linux Foundation Membership Summit
- 26 Oct 2021 - "Ceph", Carlos Maltzahn, DPS Guest Lecture at LIACS, Leiden University
- 29 Sep 2021 - "SkyhookDM: An Arrow-Native Storage System", Jayjeet Chakraborty, SNIA 2021 Presentation
- 30 Jun 2021 - "SkyhookDM: Towards an Arrow-Native Storage System", Jayjeet Chakraborty, IRIS-HEP Winter 2021 Fellowship Presentation
- 9 Mar 2021 - "Open Source Research Experience -- Summer 2021", Carlos Maltzahn, Launch of 2021 OSRE Program
- 30 Nov 2020 - "Managing Bufferbloat in Storage Systems", Carlos Maltzahn, Centre for High Performance Computing 2020 National Conference, online, South Africa
- 2 Aug 2020 - "The value of open source to universities: UC Santa Cruz tests the water", Carlos Maltzahn, Interview for a Linux Professional Institute Blog Post by Andy Oram
- 30 Jun 2020 - "The Ceph Project", Carlos Maltzahn, UC Berkeley Cloud Meetup 015
- 11 Jun 2020 - "Some lessons learned from creating and using the Ceph open source storage system", Carlos Maltzahn, BCS Open Source Specialist Group: Open source softgware for scientific and parallel computing
- 5 Jun 2020 - "How $2 Million Dollars Helped Build CROSS with Dr. Carlos Maltzahn", Carlos Maltzahn, Sustain Podcast
- 26 May 2020 - "Skyhook Data Management: programmable object storage for databases", Jeff LeFevre, Fujitsu Labs
- 15 May 2020 - "Industry-supported seeding of developer communities around university research prototypes", Carlos Maltzahn, OpenDP Community Meeting
- 27 Feb 2020 - "SkyhookDM: Programmable Storage for Datasets", Carlos Maltzahn, IRIS-HEP Poster Session
- 24 Feb 2020 - "Scaling databases and file apis with programmable ceph object storage", Carlos Maltzahn, 2020 Linux Storage and Filesystems Conference (Vault’20, co-located with FAST’20 and NSDI’20)
- 19 Nov 2019 - "Panel presentation on Enabling Data Services for HPC", Carlos Maltzahn, Enabling Data Services for HPC (BoF at SC19)
- 5 Nov 2019 - "Mapping datasets to object storage", Jeff LeFevre, CHEP 2019
- 24 Oct 2019 - "Education, research, and technology transfer in open source software: new possibilities for universities", Carlos Maltzahn, École Polytechnique Fédérale de Lausanne (EPFL)
- 21 Oct 2019 - "Education, research, and technology transfer in open source software: new possibilities for universities", Carlos Maltzahn, Friedrich-Alexander Universität, Erlangen-Nürnberg
- 19 Oct 2019 - "Center for Research in Open Source Software", Carlos Maltzahn, Google Summer of Code Mentor Summit
- 3 Oct 2019 - "Skyhook Data Management: Scaling Databases and Applications with Open Source Extensible Storage", Jeff LeFevre, CROSS Research Symposium 2019
- 15 Aug 2019 - "Update on the Center for Research in Open Source Software", Carlos Maltzahn, Seminar at New Mexico Consortium, Los Alamos
- 20 Jun 2019 - "MBWU: Benefit Quantification for Data Access Function Offloading", Carlos Maltzahn, HPC I/O in the Data Center Workshop (HPC-IODC 2019)
- 24 Apr 2019 - "Skyhook for query systems", Jim Pivarski, IRIS-HEP Topical Meetings
- 24 Apr 2019 - "Skyhook: Programmable Object Storage for Analysis", Jeff LeFevre, IRIS-HEP Topical Meetings
- 13 Mar 2019 - "How to Leverage Research Universities", Carlos Maltzahn, Linux Foundation Open Source Leadership Summit (OSLS 2019)
- 26 Feb 2019 - "Skyhook: programmable storage for databases", Jeff LeFevre, Vault'19
- 26 Feb 2019 - "Skyhook: programmable storage for databases", Carlos Maltzahn, Vault'19
- 25 Jan 2019 - "Programmable Storage Systems: For I/O that doesn’t fit under the rug", Carlos Maltzahn, Seminar at Amazon AWS
- 14 Dec 2018 - "IN53A-04: Reproducible, Automated and Portable Computational and Data Science Experimentation Pipelines with Popper (with Ivo Jimenez)", Carlos Maltzahn, IN53A: Enabling Transparency and Reproducibility in Geoscience Through Practical Provenance and Cloud-Based Workflows I (AGU Fall Meeting)
- 11 Dec 2018 - "Programmable Storage Systems: For I/O that doesn’t fit under the rug", Carlos Maltzahn, Seminar at VMware
- 16 Nov 2017 - "SkyhookDB - Leveraging object storage toward database elasticity in the cloud", Jeff LeFevre, DOMA Workshop 2017 (Flatiron Institute)
Publications
- Processing Particle Data Flows with SmartNICs, Jianshen Liu, Carlos Maltzahn, Matthew L. Curry, Craig Ulmer. Towards an Arrow-native Storage System. 2022 IEEE High Performance Extreme Computing Conference (HPEC), Virtual, September 19-23, 2022. Outstanding Student Paper (19 Sep 2022).
- Mapping Out the HPC Dependency Chaos, Farid Zakaria, Thomas R. W. Scogland, Todd Gamblin, and Carlos Maltzahn. Mapping out the hpc dependency chaos. In SC22, Dallas, TX, November 13-18 2022. (27 Aug 2022).
- Expanding the Scope of Artifact Evaluation at HPC Conferences: Experience of SC21, Tanu Malik, Anjo Vahldiek-Oberwagner, Ivo Jimenez, Carlos Maltzahn. Expanding the Scope of Artifact Evaluation at HPC Conferences: Experience of SC21. 5th International Workshop on Practical Reproducible Evaluation of Computer Systems (P-RECS), Virtual, June 30, 2022. (30 Jun 2022).
- Skyhook: Towards an Arrow-Native Storage System, Chakraborty, J., Jimenez, I., Rodriguez, S.A., Uta, A., LeFevre, J. and Maltzahn, C., 2021. Towards an Arrow-native Storage System. The 22nd IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGrid'22), Taormina (Messina), Italy, May 16-19, 2022. (16 May 2022).
- Zero-Cost, Arrow-Enabled Data Interface for Apache Spark, Rodriguez, S.A., Chakraborty, J., Chu, A., Jimenez, I., LeFevre, J., Maltzahn, C. and Uta, A., 2021. Zero-Cost, Arrow-Enabled Data Interface for Apache Spark. 2021 IEEE International Conference on Biog Data (IEEE BigData 2021), Virtual, December 15-18, 2021. (27 Nov 2021).
- Zero-Cost, Arrow-Enabled Data Interface for Apache Spark, Rodriguez, S.A., Chakraborty, J., Chu, A., Jimenez, I., LeFevre, J., Maltzahn, C. and Uta, A., 2021. Zero-Cost, Arrow-Enabled Data Interface for Apache Spark. arXiv preprint arXiv:2106.13020. (27 Nov 2021).
- SkyhookDM is now a part of Apache Arrow!, (25 Oct 2021).
- Towards an Arrow-native Storage System, Chakraborty, J., Jimenez, I., Rodriguez, S.A., Uta, A., LeFevre, J. and Maltzahn, C., 2021. Towards an Arrow-native Storage System. arXiv preprint arXiv:2105.09894. (21 May 2021).
- Enabling Seamless Execution of Computational and Data Science Workflows on HPC and Cloud with the Popper Container-Native Automation Engine, Chakraborty J, Maltzahn C, and Jimenez I. 2020 2nd International Workshop on Containers and New Orchestration Paradigms for Isolated Environments in HPC (CANOPIE-HPC, co-located with SC'20) (12 Nov 2020).
- Reproducible, Scalable Benchmarks for SkyhookDM using Popper, Chakraborty J. IRIS-HEP Summer 2020 Fellowship Report (12 Oct 2020).
- Scale-out Edge Storage Systems with Embedded Storage Nodes to Get Better Availability and Cost-Efficiency At the Same Time, Jianshen Liu, Matthew Leon Curry, Carlos Maltzahn, and Philip Kufeldt, 3rd USENIX Workshop on Hot Topics in Edge Computing (HotEdge ’20), Santa Clara, CA, June 25-26 2020 (26 May 2020).
- SkyhookDM: Data Processing in Ceph with Programmable Storage, Jeff LeFevre and Carlos Maltzahn, USENIX ;login: Magazine (12 May 2020).
- Is big data performance reproducible in modern cloud networks?, Alexandru Uta, Alexandru Custura, Dmitry Duplyakin, Ivo Jimenez, Jan Rellermeyer, Carlos Maltzahn, Robert Ricci, and Alexandru Iosup, 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’20), Santa Clara, CA, February 25-27 2020 (26 Feb 2020).
- Scaling databases and file APIs with programmable Ceph object storage, Jeff LeFevre and Carlos Maltzahn, 2020 Linux Storage and Filesystems Conference (Vault'20, co-located with FAST'20 and NSDI'20), Santa Clara, CA, February 24-25 2020 (24 Feb 2020).
- Popper 2.0: A Container-native Workflow Execution Engine For Testing Complex Applications and Validating Scientific Claims, Jayjeet Chakraborty, Ivo Jimenez, Carlos Maltzahn, Arshul Mansoori, and Quincy Wofford, Poster at 2020 Exaxcale Computing Project Annual Meeting, Houston, TX, February 3-7, 2020, 2020 (03 Feb 2020).
- Towards Physical Design Management in Storage Systems, Kathryn Dahlgren, Jeff LeFevre, Ashay Shirwadkar, Ken Iizawa, Aldrin Montana, Peter Alvaro, Carlos Maltzahn, 4th International Parallel Data Systems Workshop (PDSW 2019, co-located with SC’19), Denver, CO, November 18, 2019. (18 Nov 2019) [NSF PAR].
- SkyhookDM: Mapping Scientific Datasets to Programmable Storage, Aaron Chu and Jeff LeFevre and Carlos Maltzahn and Aldrin Montana and Peter Alvaro and Dana Robinson and Quincey Koziol, arXiv:2007.01789 [cs.DS] (Submitted to CHEP 2019) (08 Nov 2019).
- Reproducible Computer Network Experiments: A Case Study Using Popper, Andrea David, Mariette Souppe, Ivo Jimenez, Katia Obraczka, Sam Mansfield, Kerry Veenstra, Carlos Maltzahn, 2nd International Workshop on Practical Reproducible Evaluation of Computer Systems (P-RECS, co-located with HPDC’19), Phoenix, AZ, June 24, 2019. (24 Jun 2019).
- MBWU: Benefit Quantification for Data Access Function Offloading, Jianshen Liu, Philip Kufeldt, Carlos Maltzahn, HPC I/O in the Data Center Workshop (HPC-IODC 2019, co-located with ISC-HPC 2019), Frankfurt, Germany, June 20, 2019. (20 Jun 2019).
- Skyhook: Programmable storage for databases, Jeff LeFevre, Noah Watkins, Michael Sevilla, and Carlos Maltzahn, 2020 Linux Storage and Filesystems Conference (Vault'19, co-located with FAST'19), Santa Clara, CA, February 25-26 2019 (25 Feb 2019).
- Spotting Black Swans With Ease: The Case for a Practical Reproducibility Platform, Ivo Jimenez, Carlos Maltzahn, st Workshop on Reproducible, Customizable and Portable Workflows for HPC (ResCuE-HPC’18, co-located with SC’18), Dallas, TX, November 11, 2018. (11 Nov 2018).
- Taming performance variability, Aleksander Maricq, Dmitry Duplyakin, Ivo Jimenez, Carlos Maltzahn, Ryan Stutsman, and Robert Ricci, 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI’18), Carlsbad, CA, October 8-10, 2018. (08 Oct 2018).